Big Data Pipelines as Serverless Microservice's
Apache Spark vs Serverless Apache Spark, Serverless, and Microservice’s are phrases you rarely hear spoken about together, b...
Read MorePublished on Dec 22, 2019 by jhole89 on serverless, apache spark, aws step functions
Apache Spark, Serverless, and Microservice’s are phrases you rarely hear spoken about together, but that’s all about to change…
As someone who works as a SME in Apache Spark it’s been common for me to be working with large Hadoop clusters (either on premise or as part of an EMR cluster on AWS), which run up large bills even though the clusters are mostly idle, seeing short periods of intense compute when pipelines run. On top of the monetary cost of running this, the added burden of keeping these clusters healthy eats into time and energy that should be spent on adding value to the data.
In contrast we have the Serverless movement, which aims to abstract away many of these issues with managed services, where you only pay for what you use. Examples of how Serverless 1.0 has materialised is with managed compute services such as AWS Lambda and AWS Glue, services where you simply submit small scripts and define an execution runtime, paying only for the execution time and memory requirement; and managed storage services such as AWS DynamoDB and AWS S3, services where you read and write data via an API, paying only for the storage time and I/O throughput.
If we can bring these two concepts together we can leverage the power of Apache Spark to deliver value via big data solutions without the overheard of large Hadoop clusters. In doing so we can split stages into small micro-services that can easily scale independently regardless of cluster limitations, and orchestrate entire workflows (beyond apache spark) to make use of parallel execution.
Welcome to AWS Step Functions, a managed service that lets us coordinate multiple AWS services into workflows. AWS Step Functions can be used for a number of use cases and workflows including sequence batch processing, transcoding media files, publishing events from serverless workflows, sending messages from automated workflows, or orchestrating big data workflows.
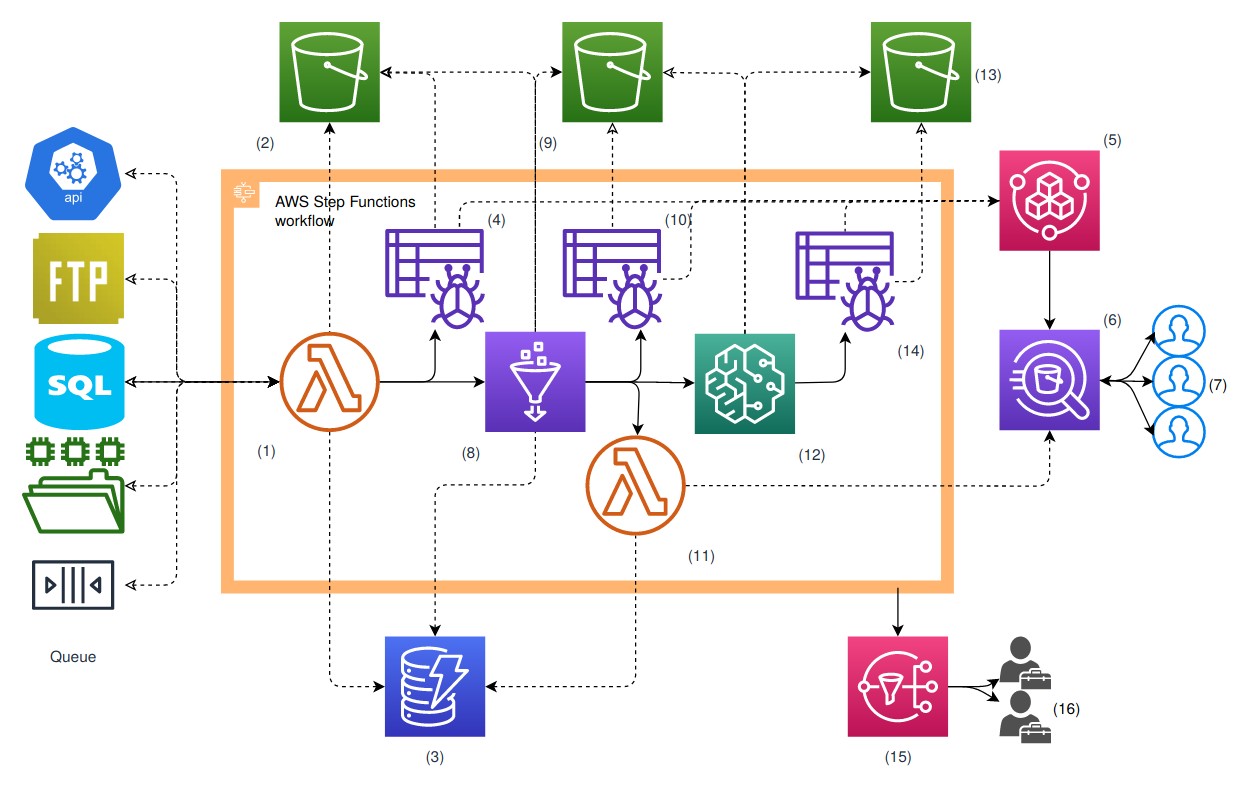
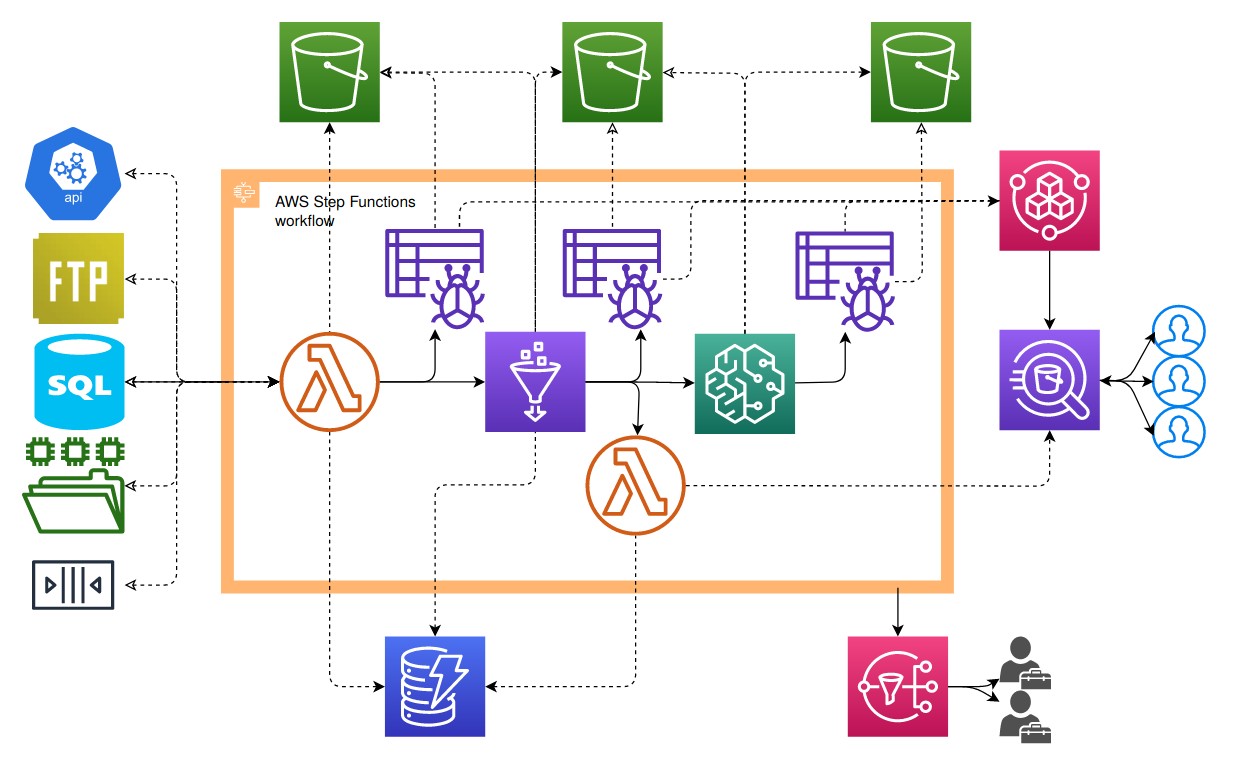
In the diagram above, we illustrate a big data workflow of sourcing data into a datalake, ETL’ing our data from source format to Parquet, and using a pre-trained Machine Learning model to predict based on the new data. This may seem complex with diverging parallel workflows, but we’ve been able to achieve a huge amount without writing much code at all - the only parts to this that actually require us to write application code are our Sourcing Lambda (1), Spark ETL (8), View Lambda (11), and Sagemaker Script (12), all of which may be less than 100 lines of code. Apart from that everything else remains a serverless managed AWS service which just need to be configured via a scripting tool such as Terraform.
On top of our primary use case of ingesting files from any external sources, landing them to S3, enriching them with
business logic and transforming the data to parquet, and using the data to predict using an ML model. Leveraging such an
architecture we have achieved the ability to:
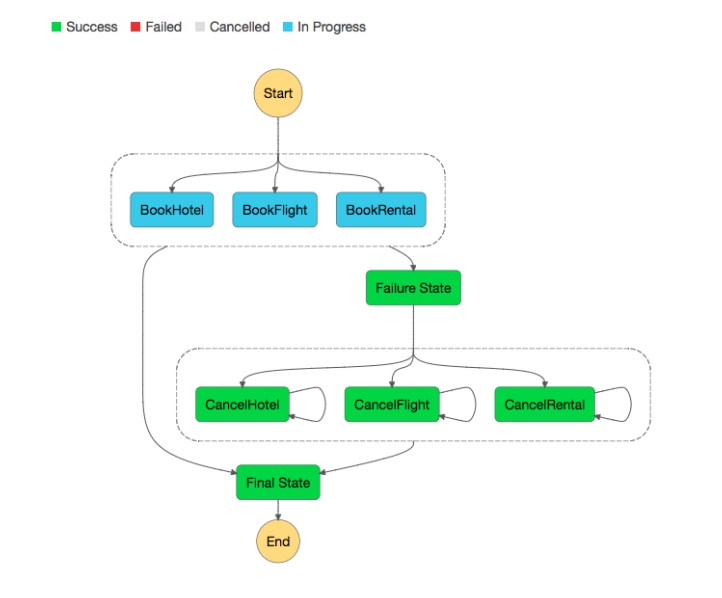
Comparing this to a traditional single stack server based architecture, we also gain numerous advantages for both the development process and service management:

As mentioned, one of the clear benefits of using AWS Step Functions is being able to describe and orchestrate our pipelines with a simple configuration language. This enables us to remove any reliance on explicitly sending signals between services, custom error handling, timeouts, or retries, instead defining these with the Amazon States Language - a simple, straightforward, JSON-based, structured configuration language.
With the states language we declare each task in our step function as a state, and define how that state transitions into subsequent states, what happens in the event of a state’s failure (allowing for different transitions depending on the type of failure), and how we want a state to execute (sequential or in parallel alongside other states).
It’s worth pointing out that some of these benefits are not limited to just AWS Step Functions. Airflow, Luigi, and NiFi are all alternative orchestration tools that are able to provide us with a subset of these benefits, in particular scheduling and a UI; however these rely on running on top of EC2 instances which in turn would have to be maintained - if the server were to go offline our entire stack would be non-functional, which is not acceptable to any high performing business, and still lacks many of the other benefits discussed such as stack level error, timeout handling, and configuration as code, among others.
AWS Step Functions is a versatile service which allows us to focus on delivering value through orchestrating components. Used in conjunction with serverless applications we can avoid waterfall architecture patterns by easily swapping in different services to fulfil roles (e.g. we could easily swap DynamoDB out for AWS RDS without any architecture burden) during development and allow developers to focus on the core use case, rather than solutionising.
As we’ve demonstrated, it can be a powerful and reliable tool in leveraging big data within the serverless framework and should not be overlooked for anyone exploring orchestration of big data pipelines on AWS. Used in conjunction with the serverless framework, it can enable us to quickly deliver huge value to without the traditional big (data) headaches.
Full architecture description is as follows:
Apache Spark vs Serverless Apache Spark, Serverless, and Microservice’s are phrases you rarely hear spoken about together, b...
Read More
I’d like to preface this by saying I don’t want this to be read as is a rant against start-ups, because I had a lot of fun ...
Read More